http://dalsa.com/sensors/products/ccd_vs_cmos.aspx#CMOSdev
Kan vara ett bra ställe att börja på om man är lite mer intresserad.
Sensorn matas alltid med samma spänning. Det går alldeles utmärkt att "multiplicera" ett enskilt pixelvärde, det är så många mellaformatskameror är konstruerade. Högre ISO är helt enkelt en digital multiplikation, avläsningen och digitaliseringen är samma hela tiden. Från sensorn finns bara en färg per pixel, så detta går alldeles utmärkt.
Normalt sett dock (vanliga kameror) ökas den analoga spänningen ut från sensorn med förstärkning innan DA-omvandlaren gör om det till en digital siffra som senare skickas till bildbehandlingsprocessorn. Detta är en betydligt bättre lösning om man inte helt enkelt vill optimera kameran stenhårt mot basISO - och så är det ju faktiskt med mellanformatare - de är tänkta att användas på basISO och inget annat. Att använda förstärkning i stället för multiplicering efter AD-omvandling ger bättre brusegenskaper på högre ISO, upp till en viss punkt iaf.
Vissa kameror med "utökat ISO-område" gör både och - när man kommer till låt oss säga ISO3200 så tar förstärkaren "slut", man kan inte vrida upp volymen mer om vi uttrycker det så. ISO högre än detta får man då via digital multiplicering av de avlästa värdena.
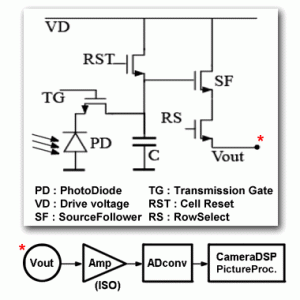
Eftersom du efterfrågade ett schema så antar jag att du kan läsa det... Håll tillgodo.
Ljus träffar PD, fotodioden, och den omvandlar då en del av fotonerna till elektrisk laddning. Under exponering är TG öppen, så laddningen kan dras till C som från början är motsatt laddad. När TG stänger så tas det inte upp mer laddning - detta kallas "elektronisk slutare" i många sammanhang... Efter exponering så används laddningen i C till att ge en utspänning via SF som "öppnar" olika mycket beroende på hur stark laddningen är och detta reglerar då spänningsfallet från VD till RS. Alla pixlarna sitter i ett stort rutnät, så för att kunna läsa ut en pixel i mitten av sensorn måste alla andra pixlar på "linan" vara isolerade, detta sköts med RS. Alla andra pixlar i en pixelrad har RS stängd medans denna pixel läses av, när avläsningen är färdig så stängs denna pixels RS och nästa pixels RS öppnas.
Vissa kameror kan mäta laddningen flera gånger för att minska felmarginalerna i avläsningen - titta på schemat så ser du att laddningen finns kvar under hela avläsningen - inte förrän RST öppnar så kan de sparade laddningarna i C "försvinna".
Ifrån "Vout" så leds spänningen till en förstärkare vars förstärkning bestämmer kamerans ISO - högre förstärkning är högre ISO - och från denna förstärkare sedan till en AD-omvandlare som skickar data vidare till DSP-kretsarna i bildbehandlingen på kameran. Här görs alla "övriga" förändringar som vitbalans, CFA-interpolering, exponeringskurvan, färgstyrka osv osv...
Schemat är en ganska standard 4T-lösning på CMOS-sensorer.

")





